![[JT]](https://www.jochentopf.com/img/jtlogo.svg) Jochen Topf's Blog
Jochen Topf's Blog
I want to write a bit about the processing architecture of osm2pgsql and how I plan to extend it to help with generalization.
(This post is part of a series about generalization of OSM data.)
The osm2pgsql architecture currently looks like this: Osm2pgsql reads an OSM file and writes the data into a bunch of tables in the database. Other programs will then read from those tables and do something with the data, for instance render it into maps.
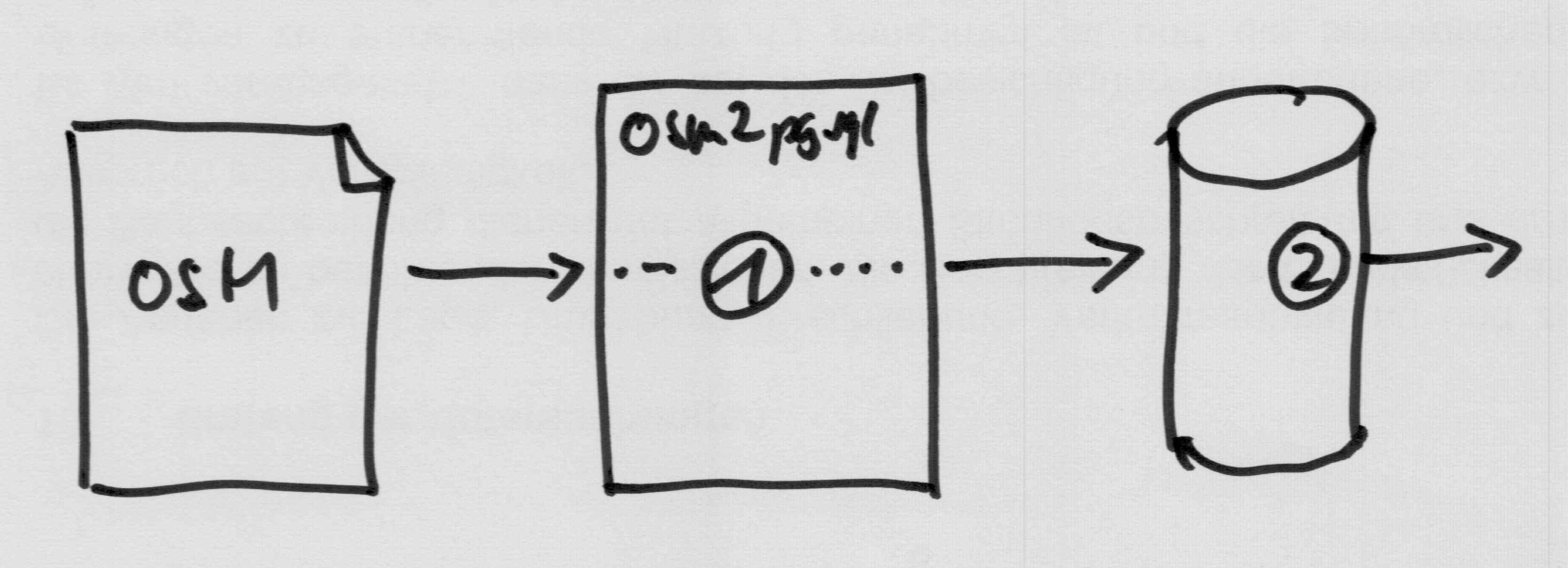
Processing basically happens in two places here. First, when osm2pgsql is reading the data (1) it can do some amount of processing. Second, when the application reads the data from the database (2) it can instruct the database to do any kind of queries. Of course the application itself can also do more processing at the end, but that doesn’t concern us here.
For the generalization we need to expand this architecture a bit. Some generalization work can be done while importing the data, but a lot of the work can only be done when all the data is available in a queryable form in the database. We could, for instance, simplify the outline of a building on import, but buildings are often connected wall-to-wall to other buildings. They need to be simplified together for good results. But the import only ever sees one single object at a time.
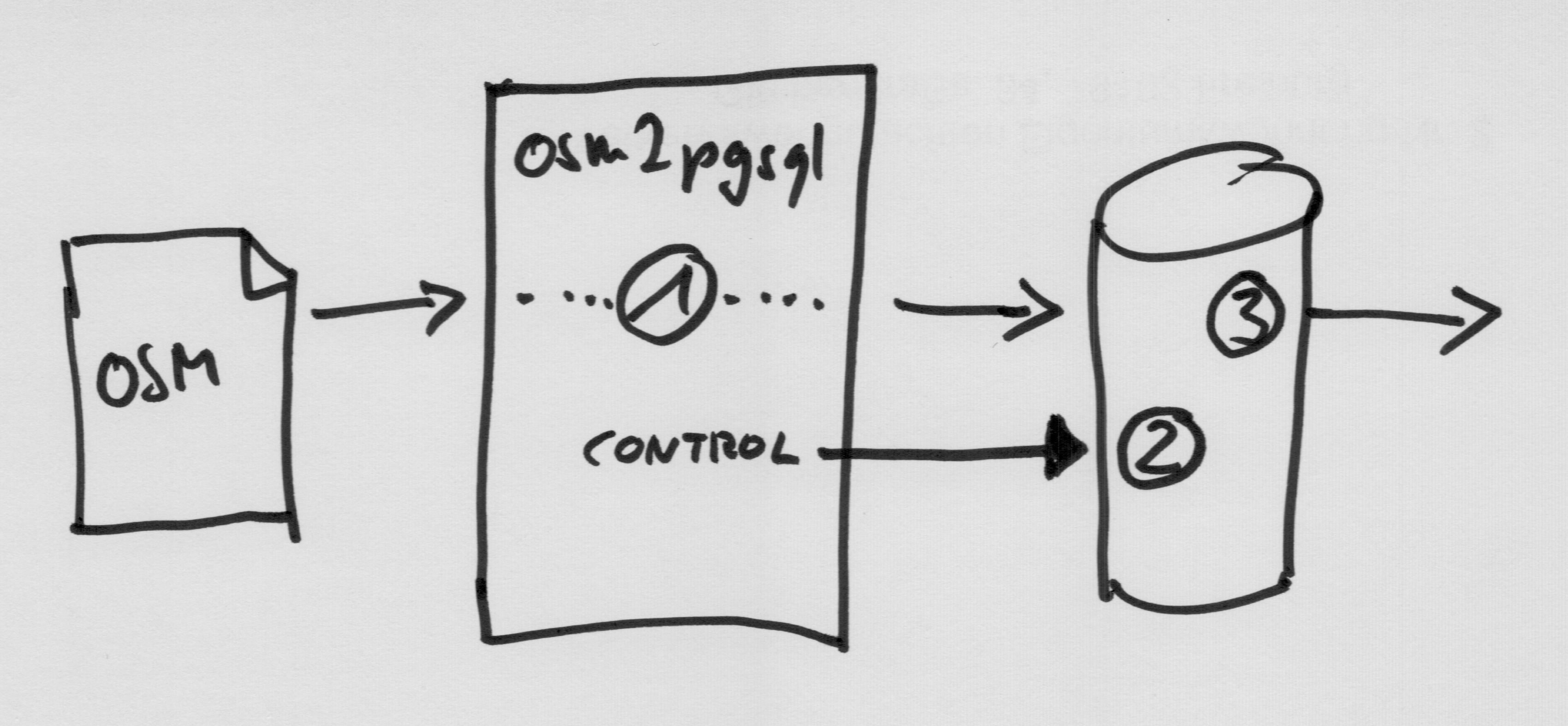
So we add another step between the import and the use of the data. We run commands in the database (2) that transform the data in some way and write the results into additional tables. Osm2pgsql controls the commands that are to be run. We do this in addition to the processing on import (1) and on export (3) which happen as before.
While it is great that we can use the power of SQL and the functions from PostGIS to do all sorts of fancy stuff, there are many processing operations which are not so easy (or fast) to do in SQL. So there is another option:
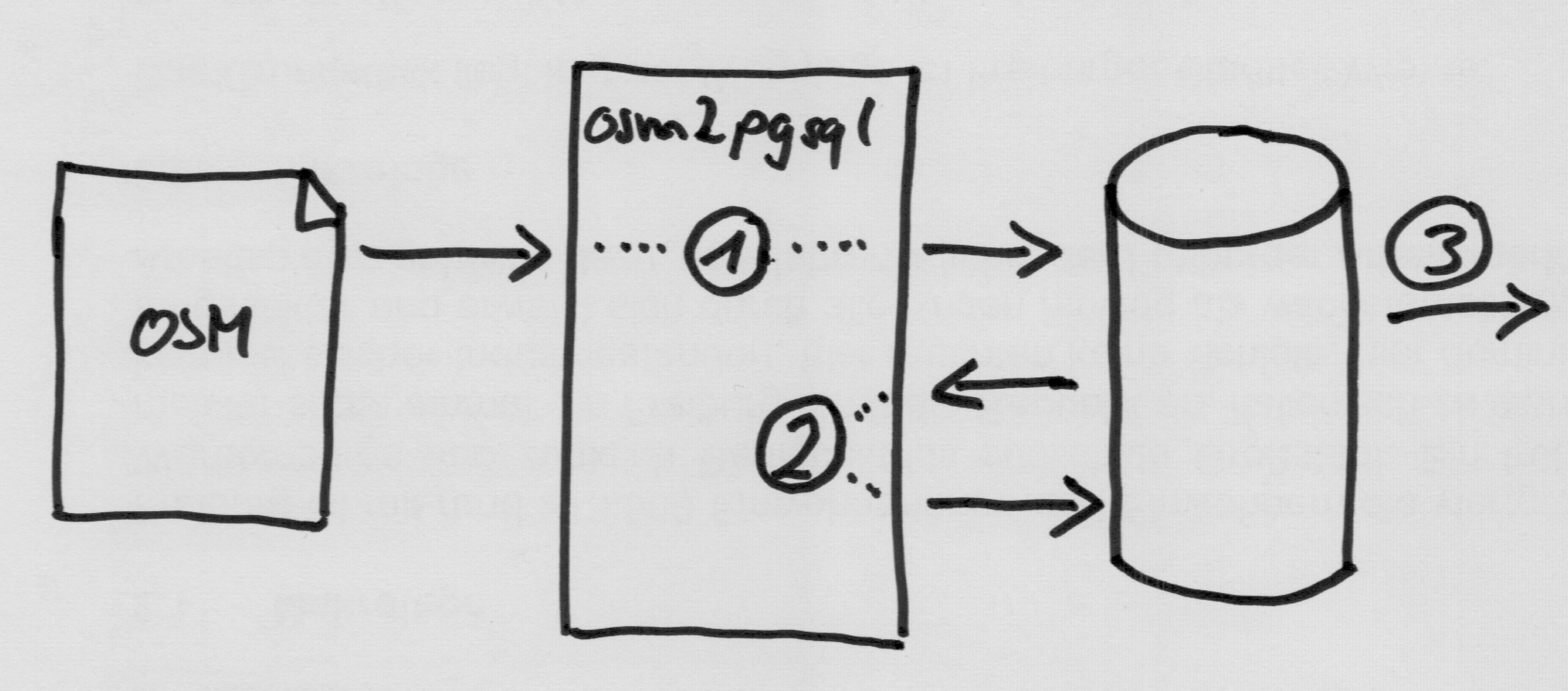
Instead of just giving commands to the database to process the data we can also read it out into osm2pgsql, process it there (2) and write it back into another table.
We could even start some external program and let it do the work:
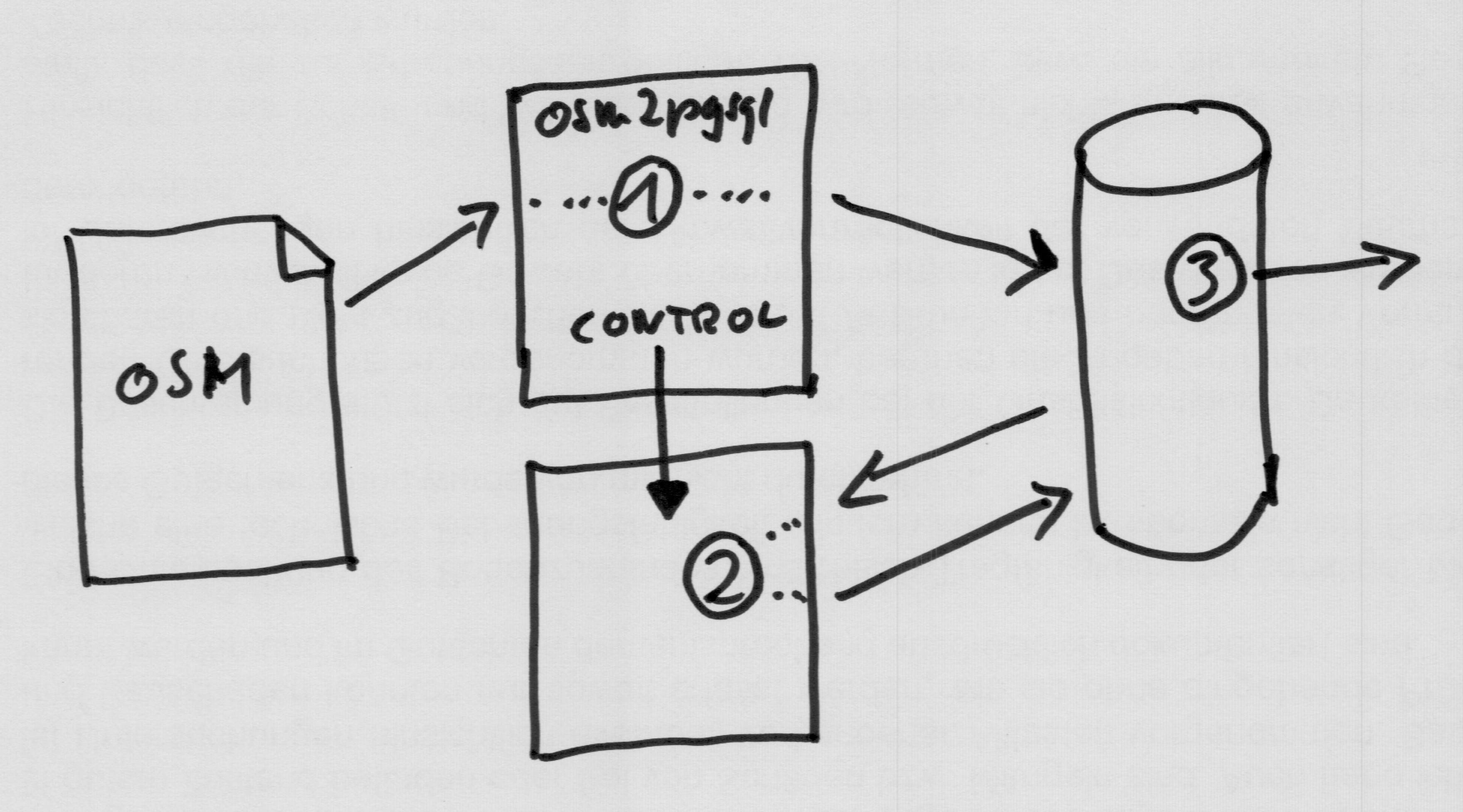
The combination of all these gives us quite a lot of flexibility, we can use SQL for some types of processing, write processing steps that need the performance in C++ inside osm2pgsql or use an external program written in Python or Go or any language we want to. Depending on the type of generalization needed we can mix and match the different approaches.
All of these processing steps (except the last one on export) have to be orchestrated by something. And osm2pgsql is the obvious choice. It does a lot of the work already, it already uses a powerful Lua-based configuration system that can be extended and it has to know about database tables and columns and indexes and all of that anyway. There are still a lot of questions to be answered about the details of all of this, but this is the rough outline.
There is one other issue I haven’t mentioned yet: OSM data changes all the time and we have to process those changes, ideally every minute. We can not re-process all the OSM data from scratch once a minute. Instead we have to look at what’s changed and do the right thing. Osm2pgsql already does this to some degree. It can read the OSM change files and figure out what data needs to be updated in the database. This mechanism has to be extended to track any changes through the chain of processing from beginning to end. This is not easy to do, especially because we need a flexible system that can accommodate different types of generalization algorithms. I’ll talk about this in a later blog post.
Of course there are other possible architectures for this process. There is a lot of overhead involved in writing the data into the database and getting it out again. There are applications like tilemaker and planetiler which do all of the processing in memory and directly spit out the finished vector tiles. That is a totally viable approach for many use cases. But the approach using the database also has its benefits. First, processing updates is much harder in the memory-only approach, because you need to keep the data around somewhere between updates, so some kind of on-disk structure is always needed. Second, using the PostgreSQL database gives us access to a huge ecosystem of modules (like PostGIS), tools and applications and it allows us to use the powerful SQL language to do some of the processing. Want to see what some intermediate processing step is doing? Just hook up QGIS to your database and look at the data. This allows for much more flexibility than a single application that does everything.
Tags: generalization · openstreetmap