![[JT]](https://www.jochentopf.com/img/jtlogo.svg) Jochen Topf's Blog
Jochen Topf's Blog
Maps almost always have lots of large and often complex polygons showing lakes, forests, urban areas, countries and so on. On a small scale map all you are going to see of some of these polygons is a few colored pixels. For that you don’t need the detailed data.
(This post is part of a series about generalization of OSM data.)
We are trying to simplify the geometry of polygons. But not all polygons can be handled in the same way. For the moment I am specifically looking at generalizing medium to large sized landcover-type objects, forests, grass or shrub or heath areas, glaciers, and so on. For them the exact outline doesn’t matter so much, because the borders are fuzzy anyway and they usually are only in the background of maps. This is different for smaller, man-made objects like buildings with many right angles which probably need different algorithms. I am also ignoring anything like administrative areas where you have several polygons that have common boundaries and need to be processed together to not get any overlaps or gaps.
For generalizing these kinds of polygons there is a commonly used solution that works pretty well: You calculate the Buffer around all the polygons, dissolve (merge) the result into one large (multi)polygon and then do another buffer operation with a negative buffer distance. A slightly better version of this does the first buffering with distance n, the second buffering after the merge with -2*n and then a third buffer with n again. The repeated buffering will get rid of small polygons and small holes in polygons as well as small spikes etc. Here is the process in images:
Original polygons in green, buffer around them outlined in black: 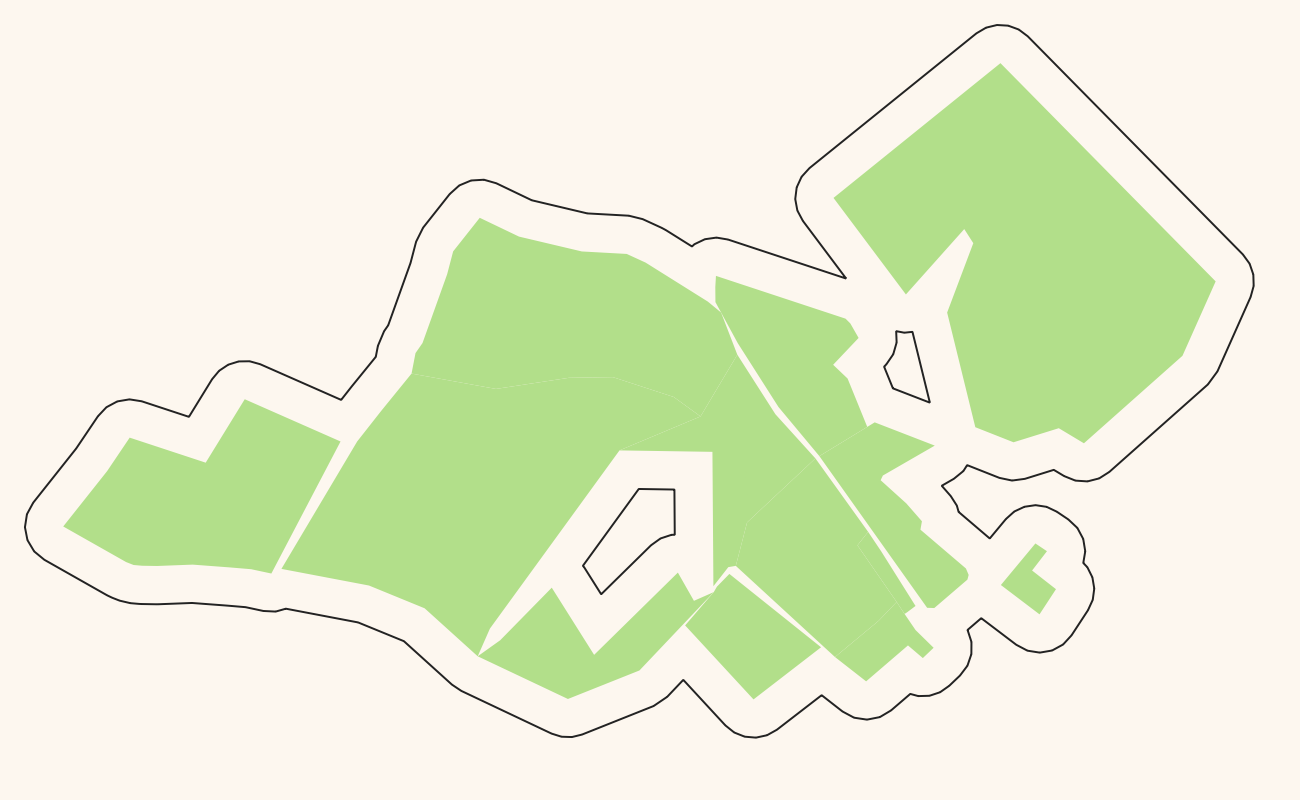
Negative buffer gives us the red polygon: 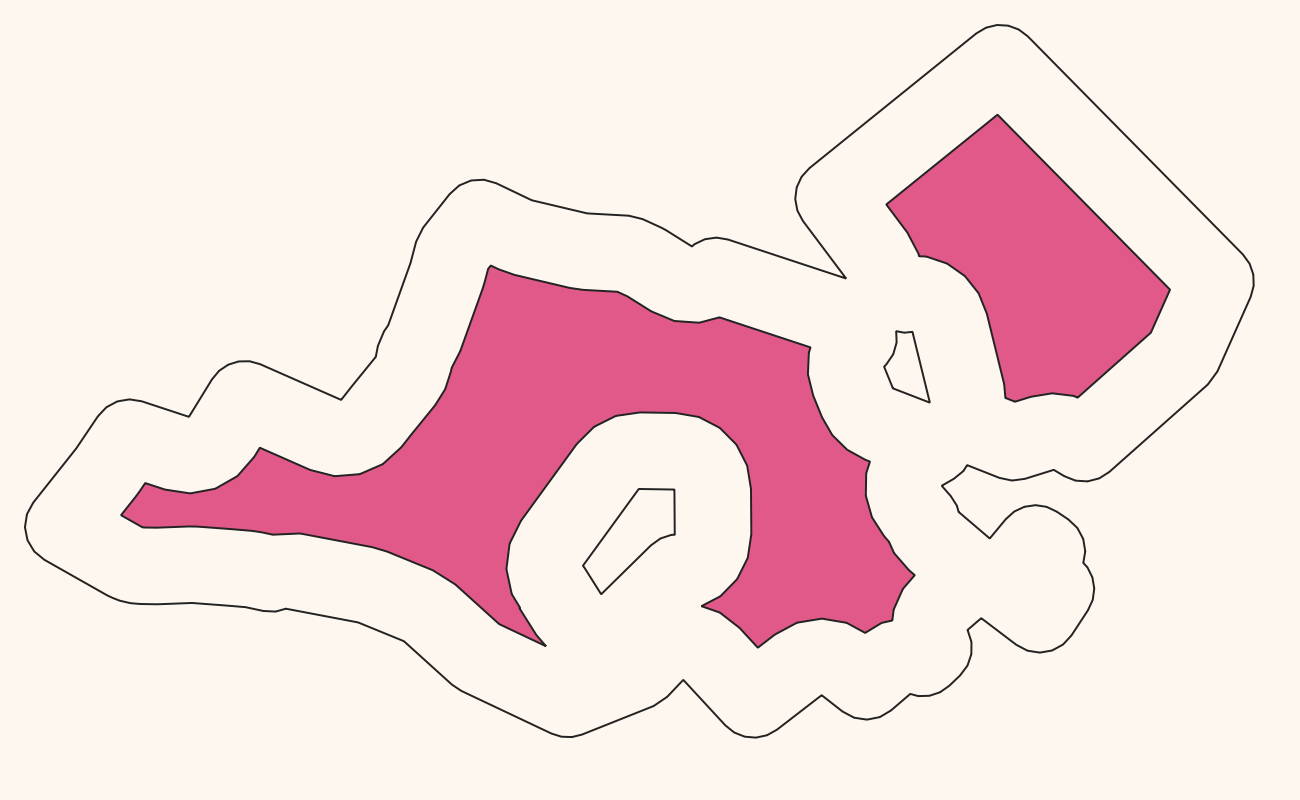
Positive buffer around the red polygon again: 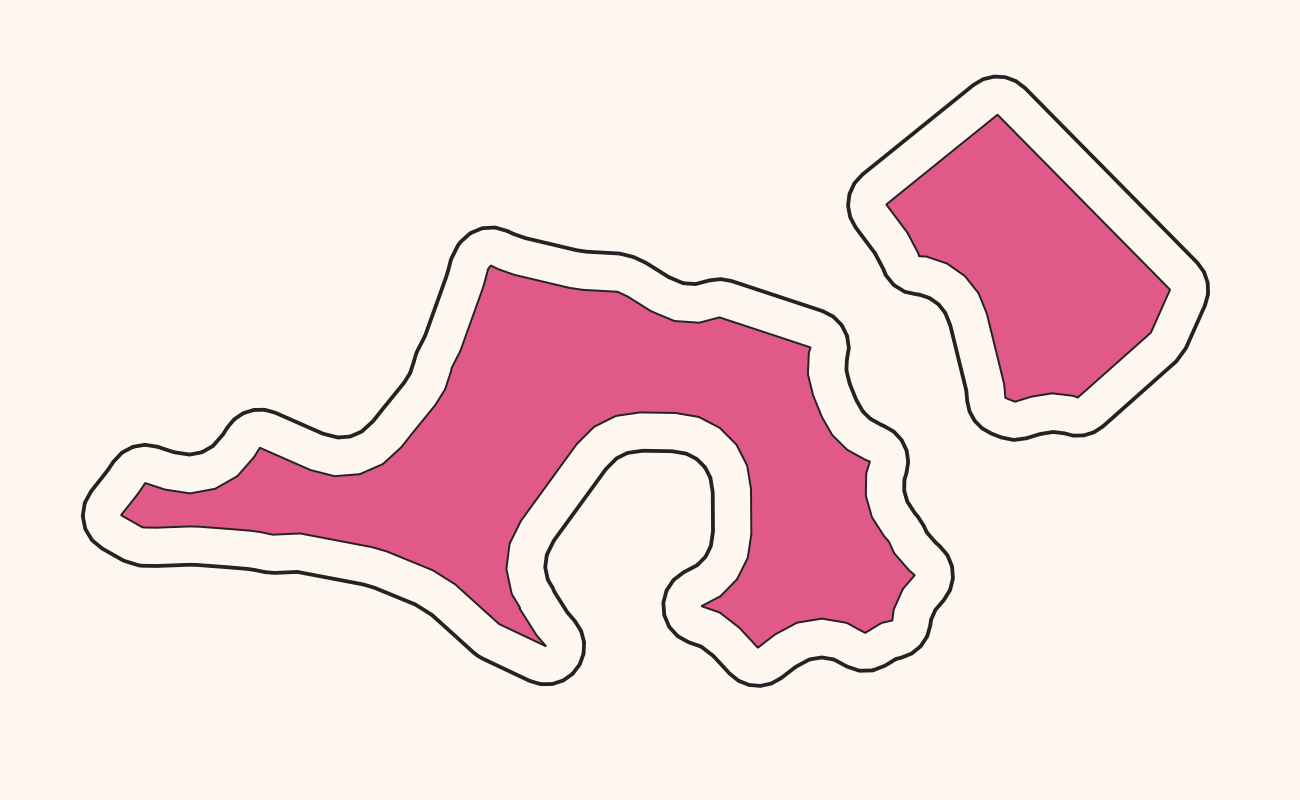
Original polygons in green, final result as black outline: 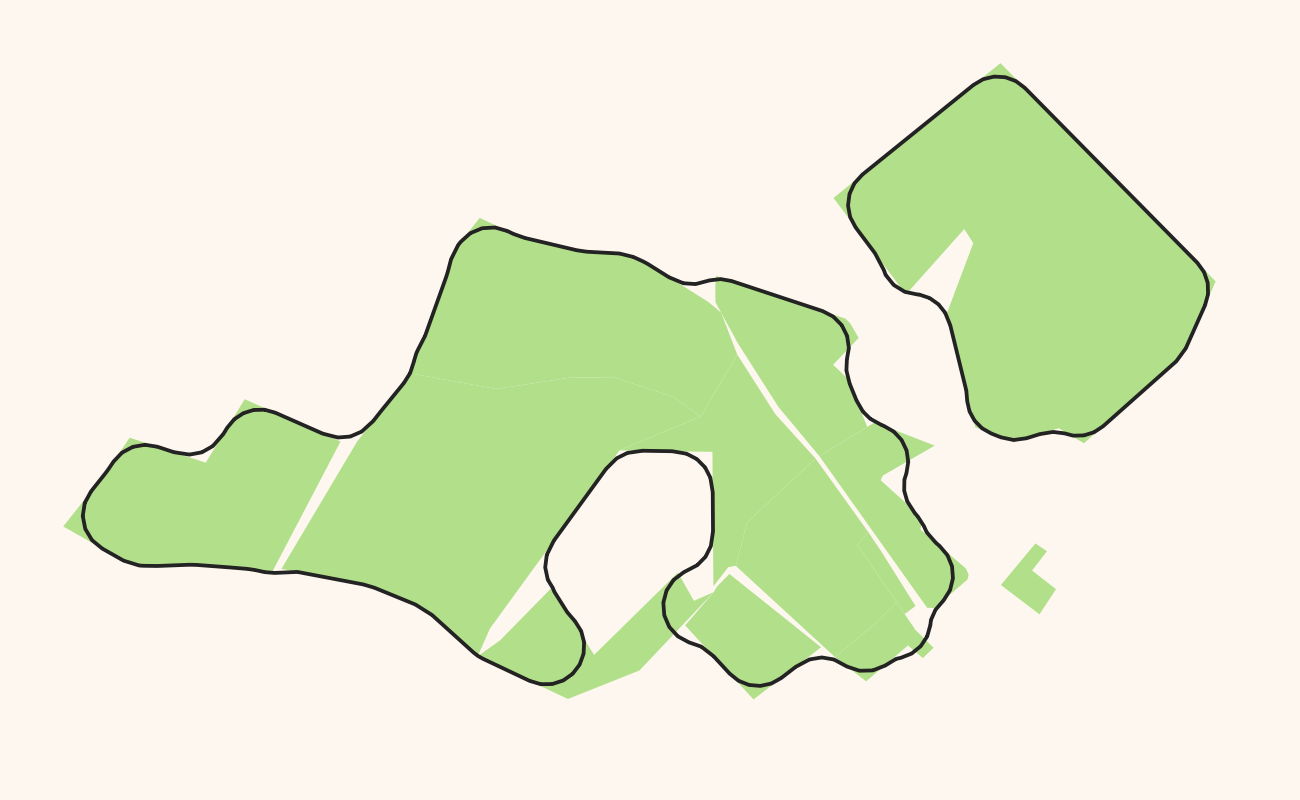
The problem with this algorithm is that it is really expensive. All the operations involved, the buffering and the merging of the many polygons into one, take a long time on complex polygons (and if they are not complex to begin with they don’t need generalization…).
There is an alternative: We can do the same operation in raster space instead of in vector space. We render the polygons into a raster, then do dilation and erosion operations (which is what the mathematicians call the buffering operations with positive and negative distance) and create vectors from the result. This sounds like a complicated way of doing things, but it turns out that it isn’t that complicated and also that it is superfast compared to the original solution. I implemented both solutions and the raster-based approach is about 10 times as fast as the vector-based approach. I timed this under real-world conditions with OSM data and using parameters that gave similar end results.
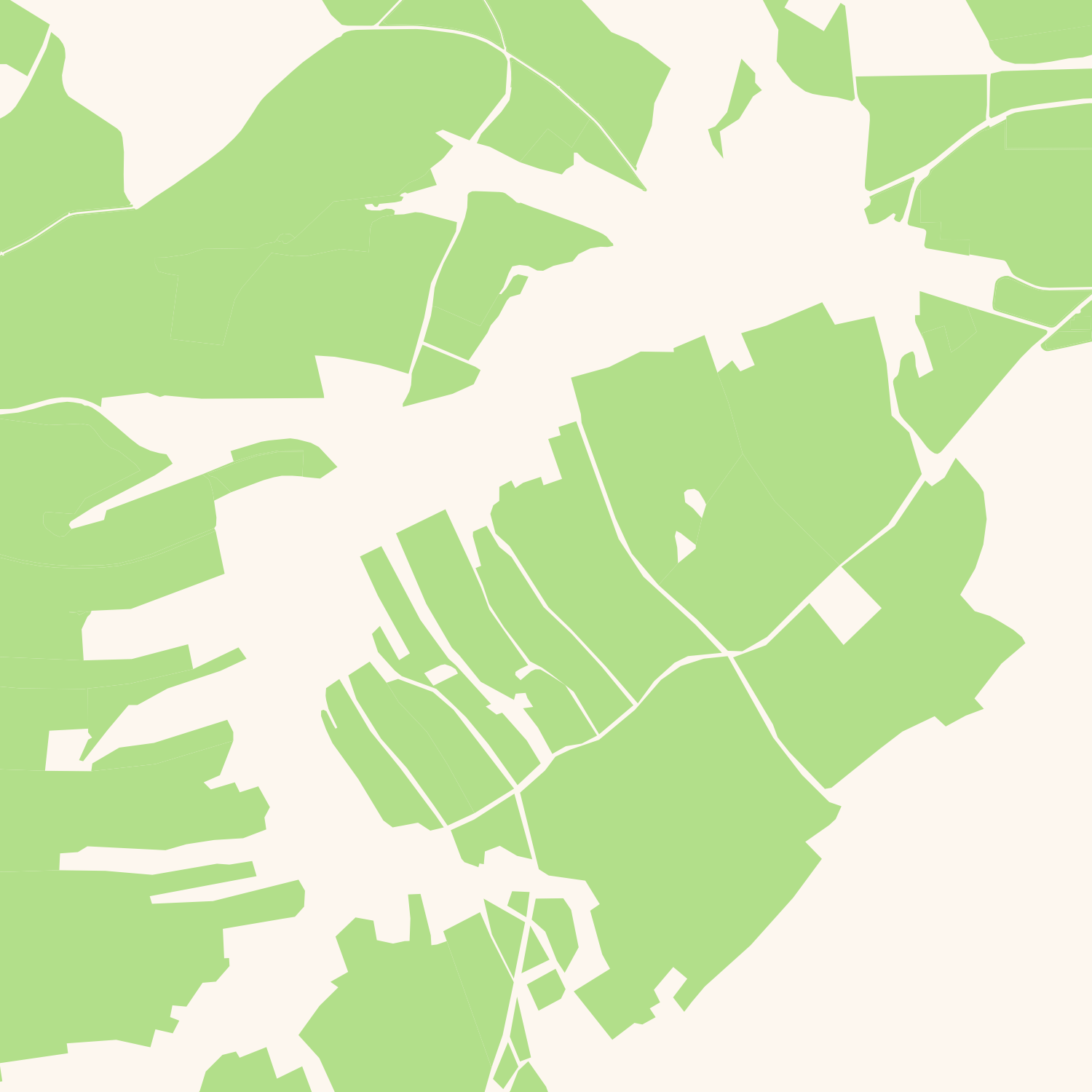

Original polygons → Rasterized version

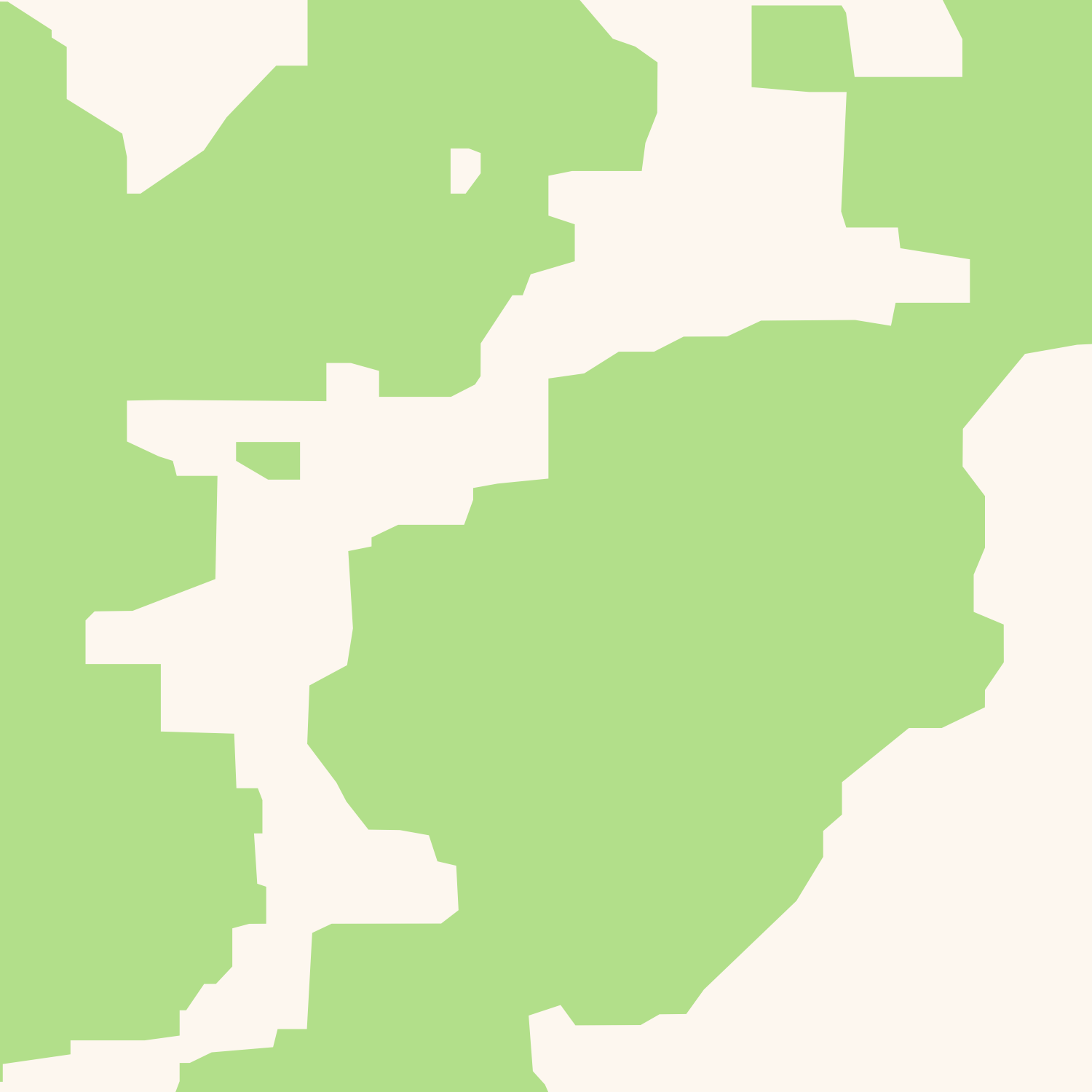
Simplified raster → Final polygons
Merging all polygons of the planet into a huge polygon or rendering all of them in a huge raster image is, of course, not a good idea. So we do what we know how: We split the planet into tiles and do this tile by tile. Depending on the use case we will be generating tiles from the data later on anyway and we can use the same tile boundaries for that. By far the most common use for osm2pgsql is in rendering maps in Web Mercator projection, so that’s all we are going to support for the time being. This makes the whole tiling thing easier. But there is no reason why the same approach wouldn’t work for other projections (and tiling schemes).
We have to do something at the tile boundaries though. We’d get ugly effects with these algorithms otherwise. But this can be solved by having some overlap, say something like 10% of the tile size. We’ll create some overlapping polygons around the boundaries with this approach but I’ll ignore that for now. If we only render colored polygons later with no opacity or other rendering gimmicks, the extra polygons will not matter. We can think about other solutions later on, like merging the overlapping polygons.
I am also going to ignore for now what’s going to happen at the 180° meridian. That needs some special case handling, it’s not difficult to solve, just a bit annoying.
I implemented both, the vector and the raster algorithms. I decided to not tie them into osm2pgsql itself though, because I don’t know yet how to best do that. Eventually we want to be able to configure the generalization from the osm2pgsql Lua config file, but it is not yet clear how this configuration will look like. So for the moment I added an extra command osm2pgsql-gen that takes a bunch of command line parameters such as the name of the source and destination tables and the parameters of the algorithms. This allows for easy experimentation (maybe you want to try it?).
I am using two libraries to help with this, CImg and potrace, both have been around for a long time and should be available everwhere. CImg is a general image library, it is used to render the polygons into a bitmap and it has the necessary dilation and erosion functions. Also it can write out the bitmaps into PNG files which comes in very handy for debugging. The potrace library does the magic that converts the bitmap back to vectors.
With the use of CImg and potrace I am following the ideas of Christoph Horman’s coastline_gen program from which I got the idea of doing these operations using rasters in the first place. (He isn’t using the potrace library though, but using the potrace command line program. And he is doing much more involved processing specifically for water features.)
The implementation is done in a way that it should be easy to plug in additional generalization algorithms as long as they are using the same tile-based approach.
With the 10x speedup compared to the vector approach it is possible to generalize the whole planet in a reasonable amount of time. Using zoom level 10 tiles for all forest/grass/rock/sand/urban polygons in OSM and rendering 10 tiles at the same time this took about an hour. This is already a big improvement over what people were using before, but there are probably some performance improvements we can make. So this looks very promising.
You can find the code in this PR. I’d love to hear from you if you try this out.
Next up I have to take care of updates, but that will be in a future blog post.
Tags: generalization · openstreetmap