![[JT]](https://www.jochentopf.com/img/jtlogo.svg) Jochen Topf's Blog
Jochen Topf's Blog
Large waterways such as rivers and canals are important features on small scale maps. This is the fourth problem I wanted to work on described in this blog post.
(This post is part of a series about generalization of OSM data.)
Rivers are mapped as linestrings and wider rivers also as polygons. As base of our processing we can’t just use the polygons, because they don’t exist everywhere. And we do need a linestring in the end. A river is not just a bunch of polygons that might or might not touch at some place, a river is a linear thing that should always be connected through its whole course.
For many rivers there are relations tagged type=waterway that collect all ways that make up a river. That sounds interesting, especially because the members can have roles main_stream and side_stream which makes it easy to just follow the main stream and discard the rest.
But there are also some problems with those river relations. First, not every river has one. So we still need some code to handle those rivers which don’t have this. Second, large relations in OSM tend to be brittle. They are easy to break accidentally when editing. So we need some code to check whether there are problems and fall back to a different solution when, say, a piece of the river is missing. With the waterway lines and polygons this is less of a problem, because breakages are easier to spot on the map and easier to fix so they tend to be okay.
An additional problem is that it isn’t always clear what a waterway relation is supposed to model. The Rhine river for instance splits up into several branches after entering the Netherlands at which point it gets several names. The Rhein relation (note the German name of the river on the relation) contains some of these branches (for instance the Waal, but not the smaller IJssel). These inconsistencies make it hard to figure out how to use those relations properly. I still think they can be used as part of the solution, for instance with helping to differentiate between main and side channels, but I leave that for the future.
So we are going primarily with the ways tagged as waterway and also use additional data as needed and where available. We are only looking at waterways tagged as river or canal. Streams, ditches etc. are too small to matter for our use case here. The canals are needed because some rivers have been canalized and are tagged as such but we still want to render them.
Before we can do anything else, we have to decide on some criteria for selecting the rivers we want to show. The amount of water flowing down the waterway on average is probably a good measure, but we don’t have that information. What we do have, at least for some rivers, is the width of the waterway. Rivers might have different depths and flow speeds, so width isn’t the same as the amount of water, but its close enough, and arguably even more important, because a wider river certainly looks more important than a narrow one.
Unfortunately only about 2% of ways tagged as waterway=river have a width tag. But we have something else: Lots of rivers, especially the large ones, are not only mapped as a linestring but also as a polygon. We can figure out how wide those polygons are and then add that width to the ways which don’t have one. This process doesn’t have to be perfect, we will simplify those linestrings later anyway, it just has to be good enough to give us a rough approximation how wide a stretch of the river is so that we can decide whether this river should make it onto the map.
It took some experimenting, but I found a way to do just that. For every waterway polygon we use the PostGIS ST_MaximumInscribedCircle() function to calculate the “width” of that polygon. Then we can find all waterways intersecting the polygon and add the width to those ways. The details are a bit more complex, but it works reasonably well for most of the cases I tested. (The code will be available together with the other stuff I am describing here soon.)
What we have now are lots of ways, some of which have an additional width property. Those that don’t are smaller rivers that didn’t have a width tag to begin with and are not mapped as polygon. But that’s okay, because we don’t want to render those small rivers on low zoom levels anyway.
But we still need to create longer, complete linestrings from the pieces we have. A river can sometimes be wider and then become narrow again. We don’t want the wider pieces to show up on the map and the more narrow ones hidden.
To fix this we need to build the network of all the rivers. First we split up all way geometries into segments (each connecting two points). Then we re-assemble those segments into pieces going from one branching point to the next creating a directed graph. Each edge in that graph gets the largest width property of all its segments. Then we walk through that graph downstream, each edge gets as width either the width it had before or the upstream width, if that was larger. So this way a river only ever gets wider, never narrower. If we draw all rivers wider than a certain value, we always have a continuous line from the place where it first was wider than that minimum value down to the sea.
Creating this graph and working with it is rather difficult to do in SQL and quite expensive. Instead we just read all the data from the database and do the processing in C++. Using reasonably efficient data structures and algorithms this runs in a few minutes for the whole of Europe and needs only a few GB of memory. (There are probably ways to make this even more efficient, but its good enough for now.) After processing the data is simply stored in the database again in an extra table.
There are some problems with this algorithm. A river can split into several branches which, in this case, will all get the same width property. If they join up again after a short stretch this doesn’t matter much. But if they diverge and run into the sea in different places, you’ll not get the right result, for instance in the already mentioned case of the Rhine splitting into Waal/Nederrijn/Lek/IJssel. The Po river in northern Italy is another case where this doesn’t work so well due to the extensive canal network there.
You can see the result in this image. All rivers and canals are in blue and the assembled rivers wider than 200m in red. Click on the image to get a large version.
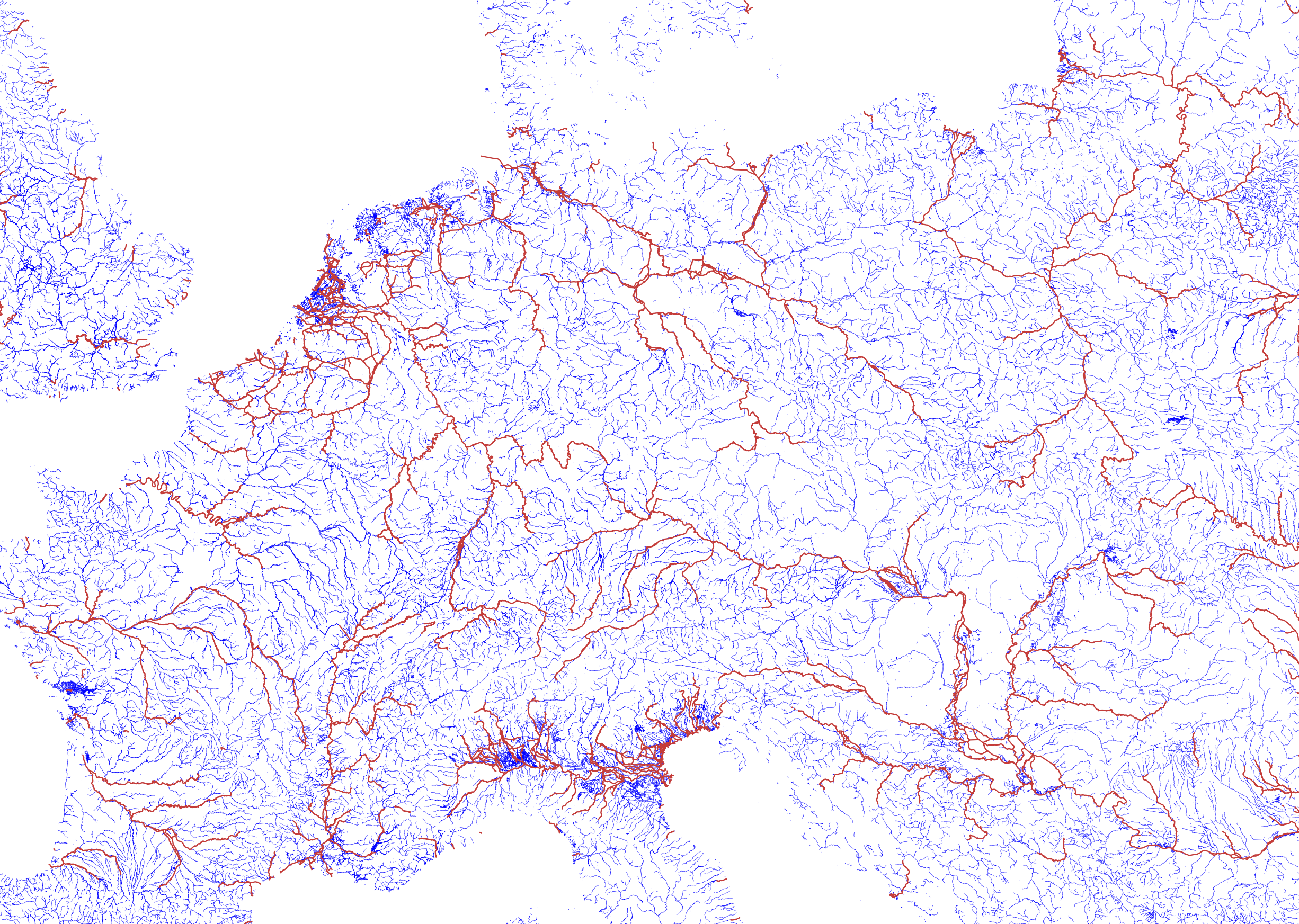
I have glossed over a lot of detail here and there are still many problems. This is far from a complete solution, but I would classify the current state as “promising”. I probably have to remove rivers that are shorter than some value. This happens most often for small rivers that nevertheless have a wide mouth where they flow into the sea. And I still have to actually do the simplification of the linestrings themselves and sort out the name labelling.
What’s interesting about the solution I am using here is that it contains a part which uses the strength of the PostgreSQL/PostGIS database (merging the linestring and polygon data to get the width onto the linestrings) with a part that uses the strength of a C++ program (assembling the network and propagating the width property downstream). Had I only one tool at my disposal this would have been much harder to do. And the code building the river network can hopefully be also used for other network-type data such as road or railway networks.
Tags: generalization · openstreetmap