![[JT]](https://www.jochentopf.com/img/jtlogo.svg) Jochen Topf's Blog
Jochen Topf's Blog
Many maps show built-up areas of cities and other settlements in a different color on scales where you can’t show individual buildings. This gives the viewer an immediate idea on where the landscape is more urban and where it is more rural. This is the third problem I wanted to work on described in this blog post.
(This post is part of a series about generalization of OSM data.)
There are ways to map urban areas in OSM with landuse=residential, industrial, commercial, retail and the like. In addition we need some other types of sometimes large areas like leisure=stadium or amenity=university. Although a university campus can be quite green for instance, I would still count it as part of the urban area and if we don’t take it into account it can leave large “holes” in the area of the city.

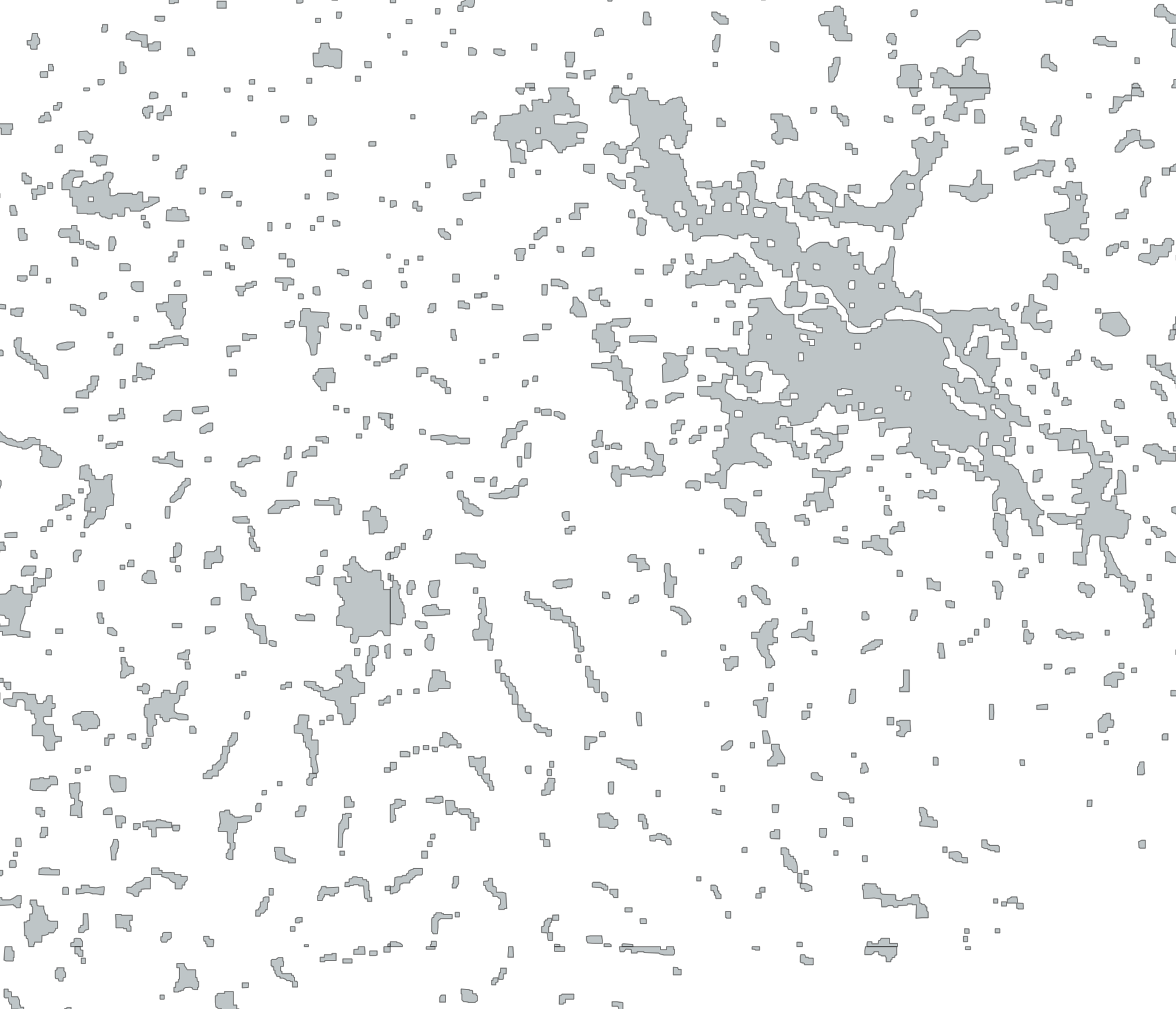
Left: landuse type tags src data, right: generalized data. (Click on any image to enlarge.)
This works reasonably well in large parts of Europe where landcover type mapping is quite universal and complete. But it doesn’t work everywhere. There are large parts of the US and many other countries around the globe where those tags are not available.
So in addition to those tags we need to look at some other data. An obvious choice are buildings. An area with lots of buildings is also a built-up area.
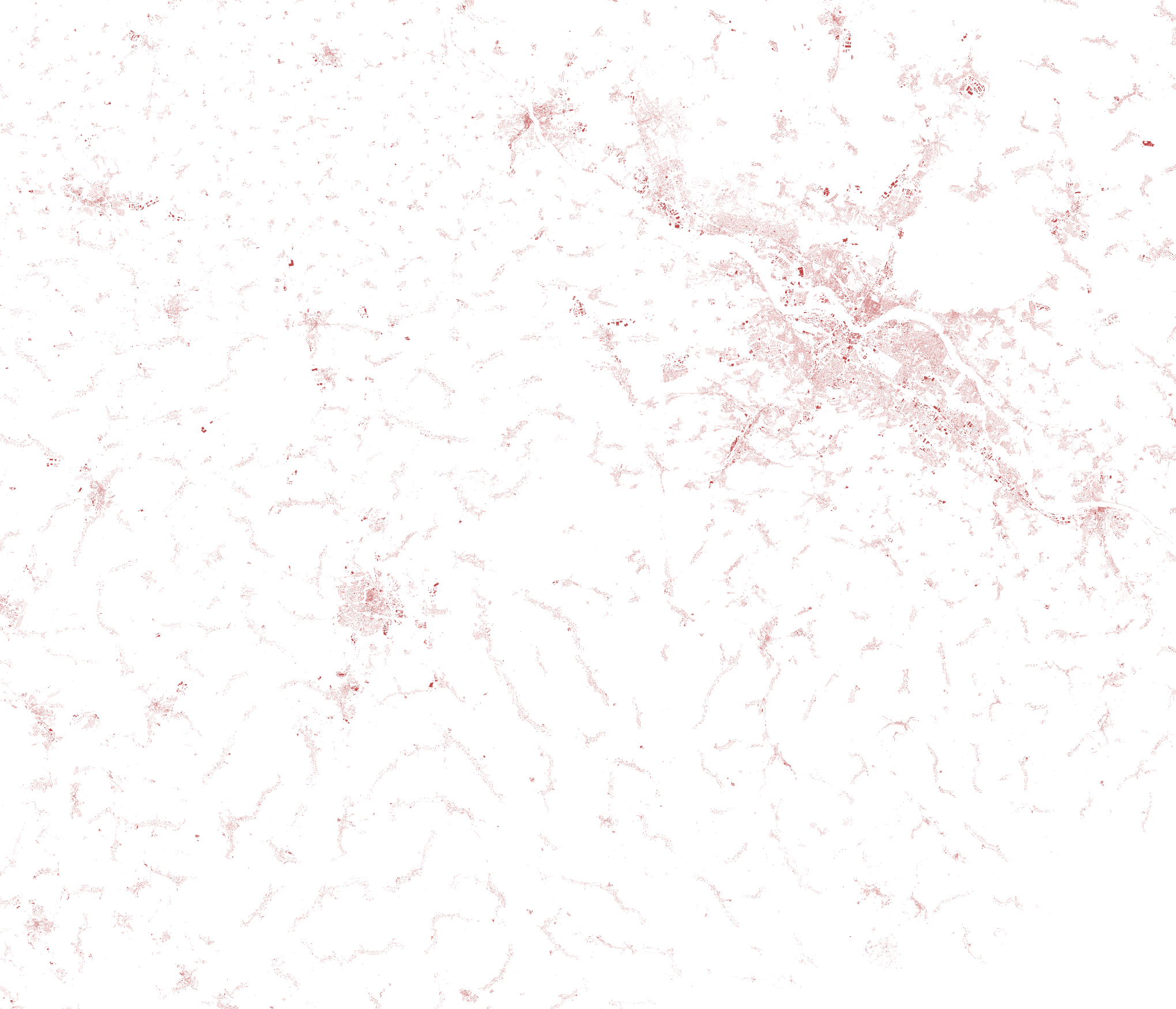

Left: buildings, right: areas with lots of buildings
But this is still not enough. In some parts of the world, building cover is rather sparse, but there are roads. A dense network of residential roads also indicates a built-up area. This is a rather complex issue though, because mapping of road types is rather bad in some areas, especially in the US where the TIGER import tagged many roads as residential that are in reality only tracks with maybe a few houses here or there (and often not even that).
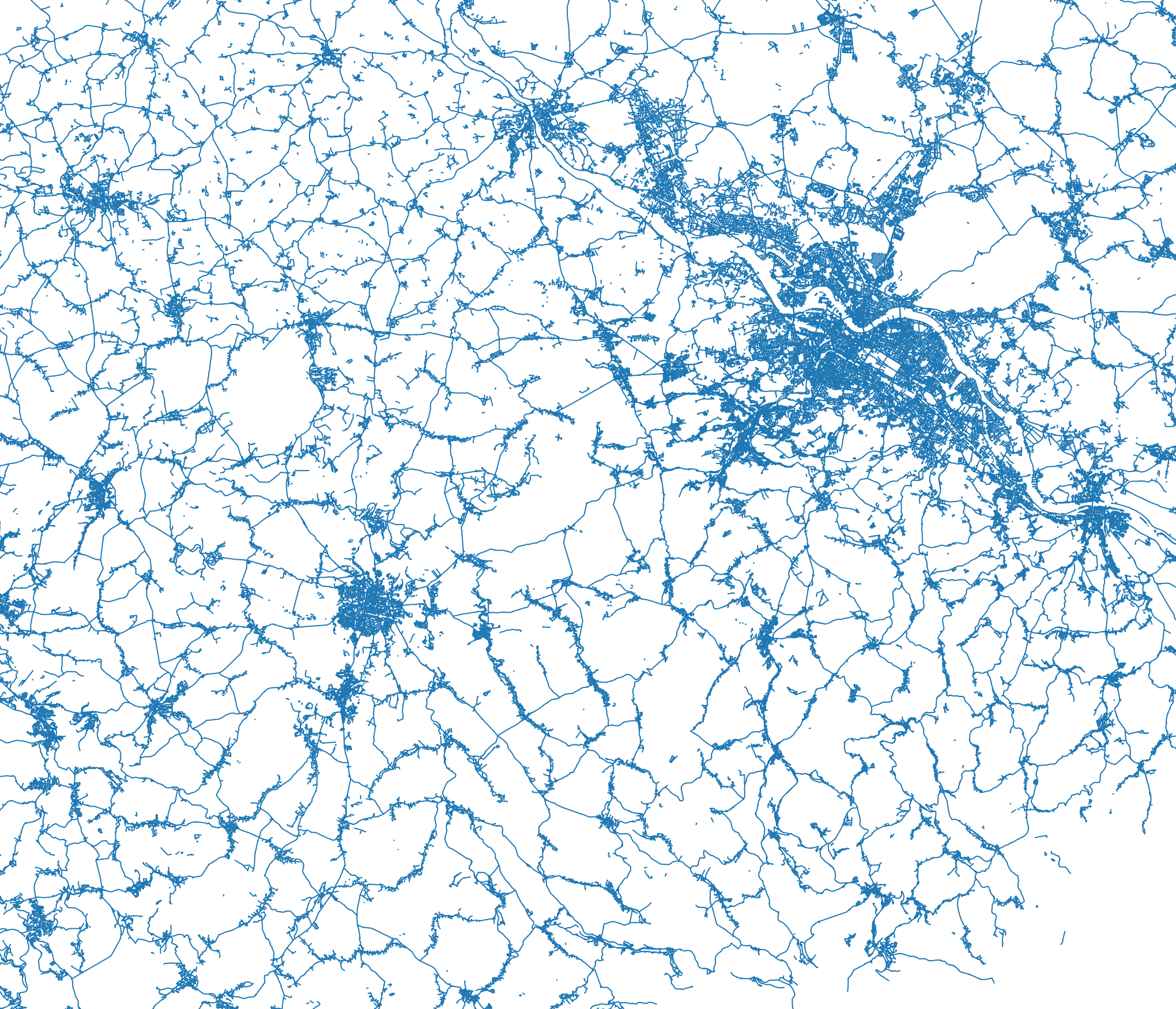
Left: roads, right: areas with dense road network
I still decided to add roads to the source data, because from the examples I looked at it still seemed somewhat useful. But it might be better to do this on a country-by-country basis.
I also looked at another indicator, the place tags. You would expect that built-up places have place tags with names in their vicinity. I tried to only count an area as built-up if there is a place node near the area. But the tagging is quite inconsistent, in some regions this works better than in others and it is unclear how far away is still “near”. So in the end I did not use that, but I could still imagine this being part of some heuristic.
I first used the already described mechanism to derive built-up areas separately from the landcover, buildings, and roads as mentioned above and fiddled around with the parameters to find the best results from visual inspection in some areas of the world.
I then simply merged those three results, everything that’s detected as built-up in at least one of the three layers is built-up. I thought about some more complex heuristics and tried, as mentioned, to bring in places, too. But in the end the simplest things often work best.
I implemented this as another “generalizer” in my code which can specifically deal with several input layers with different buffer parameters and then creates the union of the generated rasters before doing the vectorizing step.
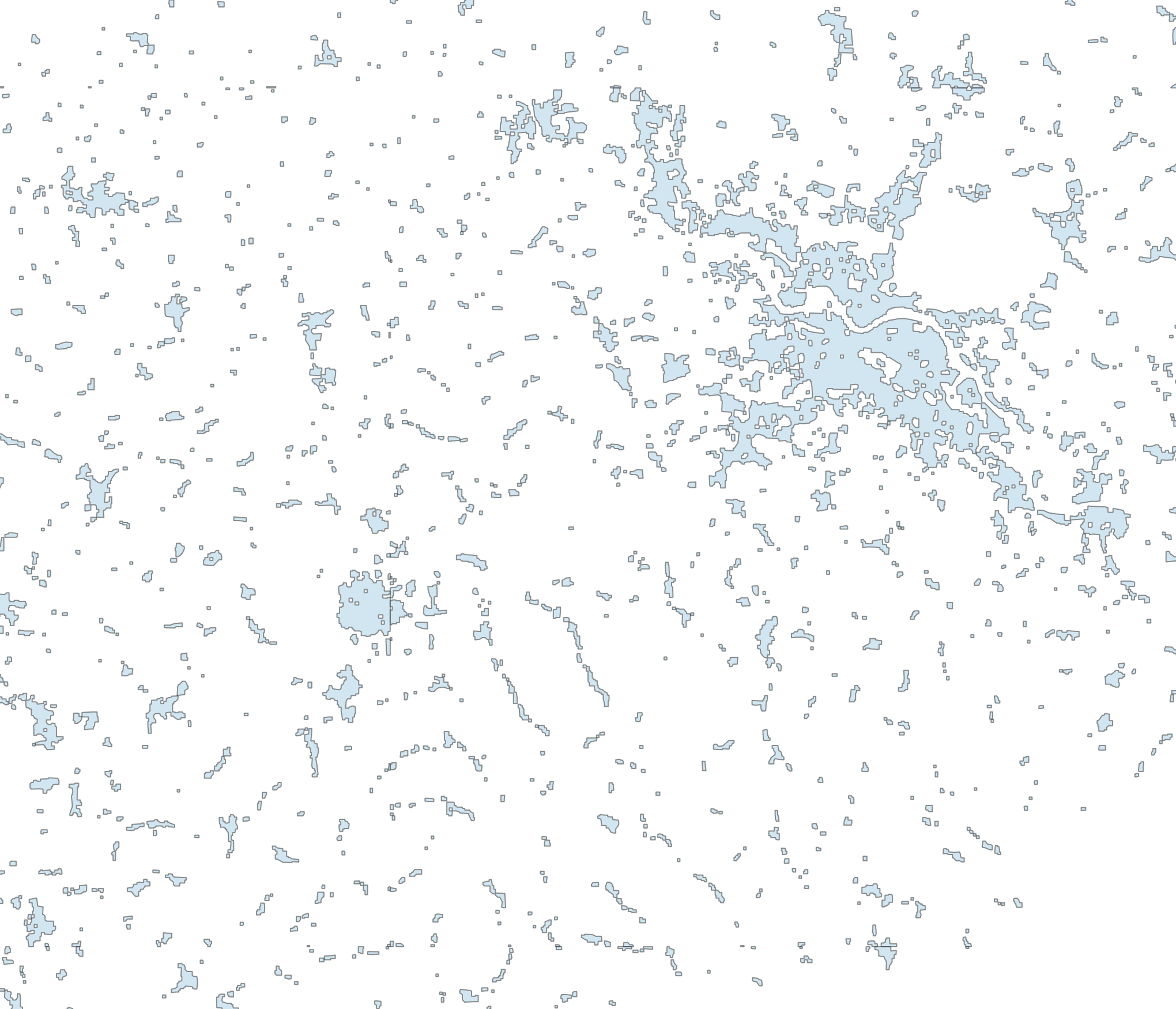
Here you can see the separately generalized data rendered as separate layers:
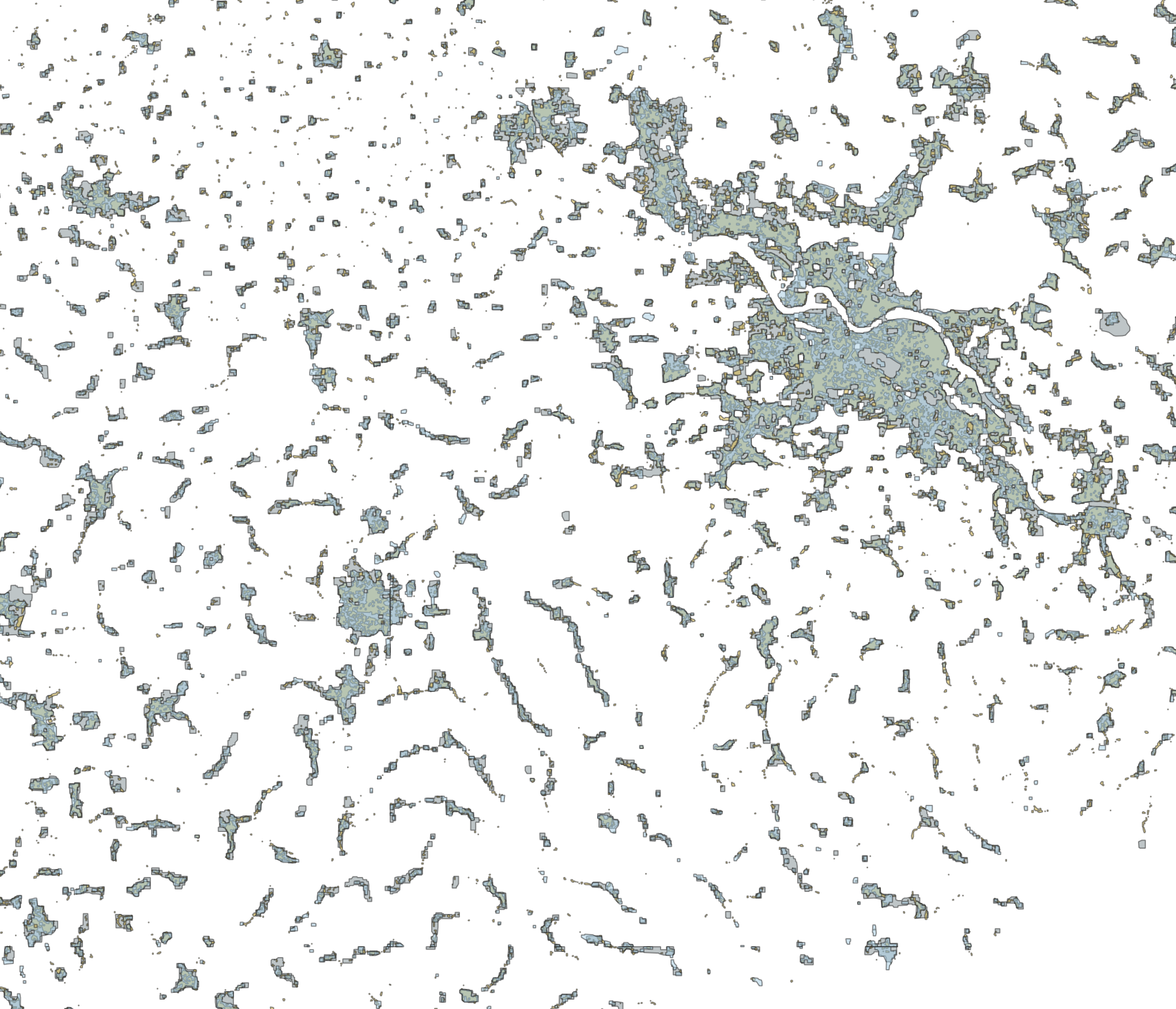
And this is the final result in which all small areas (and small holes in larger areas) have been removed:
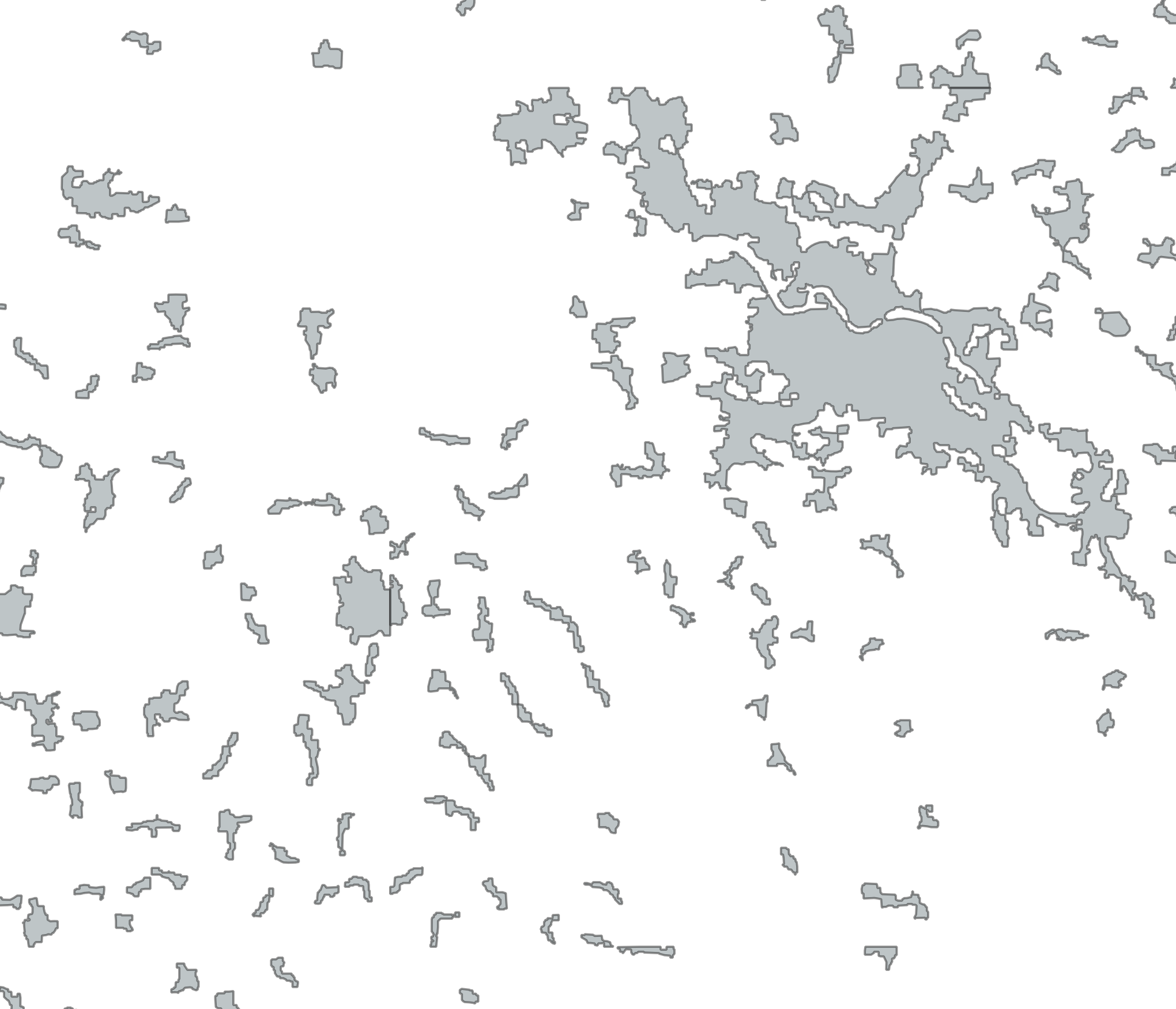
After doing all this, I am not so sure any more how important the urban vs. rural distinction is in maps. In Europe you mostly see quite clear borders between rural and urban areas, but in other parts of the world this is not always so. But the cartographer of every specific map has to decide that. Similarly the choice which tags to use for the input data and what parameters to use for the generalization very much depends on the output map type and scale.
I am not sure how useful the hard-coded “builtup” generalizer code is. It is somewhat flexible (input layers, buffer), but not flexible enough for more varied experiments (how to merge the layers, for instance). Computationally it is about three times as expensive as the “raster-union” generalizer, because it basically does the same thing three times for the three input layers. There’s is probably some room for improvement there.
Tags: generalization · openstreetmap